數(shù)字技術(shù)有限公司")






引言
在數(shù)據(jù)分析領(lǐng)域,CSV(逗號分隔值)文件是一種非常常見的數(shù)據(jù)存儲格式。由于其簡單性和靈活性,CSV文件被廣泛應(yīng)用于數(shù)據(jù)交換和存儲。然而,隨著數(shù)據(jù)量的不斷增長,讀取CSV文件的速度成為了一個(gè)關(guān)鍵問題。本文將探討如何高效地讀取CSV文件,以提高數(shù)據(jù)處理效率。
選擇合適的工具
在讀取CSV文件時(shí),選擇合適的工具至關(guān)重要。以下是一些流行的工具,它們都提供了高效讀取CSV文件的功能:
- Pandas:Python中一個(gè)強(qiáng)大的數(shù)據(jù)分析庫,提供了豐富的數(shù)據(jù)結(jié)構(gòu)和數(shù)據(jù)分析工具,可以輕松讀取和操作CSV文件。
- NumPy:Python中一個(gè)基礎(chǔ)的科學(xué)計(jì)算庫,雖然本身不直接支持讀取CSV文件,但可以與Pandas結(jié)合使用。
- Python的內(nèi)置csv模塊:適用于簡單的CSV文件讀取任務(wù)。
- Java的OpenCSV:適用于Java編程語言,提供了高效的CSV文件讀取功能。
- Excel:雖然主要用于數(shù)據(jù)可視化,但也可以快速打開和讀取CSV文件。
使用合適的數(shù)據(jù)類型
在讀取CSV文件時(shí),指定正確的數(shù)據(jù)類型可以顯著提高效率。以下是一些常見的CSV文件數(shù)據(jù)類型及其在Pandas中的對應(yīng)類型:
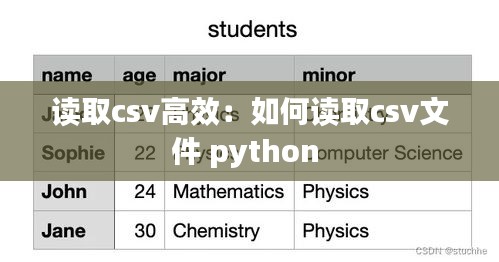
- 整數(shù):`int`
- 浮點(diǎn)數(shù):`float`
- 字符串:`str`
- 布爾值:`bool`
如果CSV文件中的數(shù)據(jù)類型不明確,可以使用Pandas的`infer_objects()`方法自動推斷數(shù)據(jù)類型,但這種方法可能會降低讀取速度。
使用適當(dāng)?shù)姆椒ㄗx取數(shù)據(jù)
不同的工具和庫提供了不同的方法來讀取CSV文件。以下是一些提高讀取效率的方法:
- 使用迭代器:對于非常大的CSV文件,使用迭代器可以逐行讀取數(shù)據(jù),而不是一次性將整個(gè)文件加載到內(nèi)存中。
- 使用塊讀取:一些庫允許按塊讀取數(shù)據(jù),這可以減少內(nèi)存使用并提高速度。
- 跳過不需要的列:如果CSV文件包含一些不需要的列,可以只讀取需要的列,以減少處理時(shí)間。
- 使用緩沖區(qū):一些庫允許調(diào)整緩沖區(qū)大小,以優(yōu)化內(nèi)存使用和讀取速度。
并行處理
對于非常大的CSV文件,可以考慮使用并行處理來提高讀取效率。以下是一些實(shí)現(xiàn)并行處理的方法:
- 多線程:在Python中,可以使用`concurrent.futures`模塊來創(chuàng)建多線程任務(wù),并行讀取CSV文件的不同部分。
- 多進(jìn)程:在Python中,可以使用`multiprocessing`模塊來創(chuàng)建多進(jìn)程任務(wù),利用多核CPU的優(yōu)勢來并行處理數(shù)據(jù)。
- 分布式處理:對于非常大的數(shù)據(jù)集,可以使用分布式計(jì)算框架,如Apache Spark,來在多臺機(jī)器上并行處理數(shù)據(jù)。
優(yōu)化讀取性能的技巧
以下是一些優(yōu)化CSV文件讀取性能的通用技巧:
- 使用壓縮文件:如果CSV文件很大,可以考慮將其壓縮,以減少讀取時(shí)間。
- 避免使用索引:如果不需要對CSV文件進(jìn)行隨機(jī)訪問,可以關(guān)閉索引,以減少讀取時(shí)間。
- 優(yōu)化數(shù)據(jù)格式:對于復(fù)雜的CSV文件,考慮優(yōu)化數(shù)據(jù)格式,例如使用更緊湊的數(shù)據(jù)類型或減少數(shù)據(jù)冗余。
結(jié)論
高效地讀取CSV文件對于數(shù)據(jù)分析和處理至關(guān)重要。通過選擇合適的工具、使用合適的數(shù)據(jù)類型、采用適當(dāng)?shù)姆椒ā⒉⑿刑幚硪约皟?yōu)化讀取性能,可以顯著提高CSV文件讀取的效率。這些技巧可以幫助您更快地處理數(shù)據(jù),從而更好地利用數(shù)據(jù)分析和處理的優(yōu)勢。
轉(zhuǎn)載請注明來自福建光數(shù)數(shù)字技術(shù)有限公司,本文標(biāo)題:《讀取csv高效:如何讀取csv文件 python 》








 蜀ICP備2022005971號-1
蜀ICP備2022005971號-1
還沒有評論,來說兩句吧...